Prometheus의 라이프사이클
1) 메트릭을 수집하고, 시계열로 저장합니다.
2) 메트릭을 측정하고, 리소스를 오토스케일링 처리합니다.
3) 변경된 리소스를 자동으로 디스커버리합니다.
4) HPA와 연계하여 증가한 리소스로 유저 트래픽을 분산시킵니다.
부록 1) Prometheus에서 레이블이 미치는 영향
레이블 조합에 따라서 카디널리티(메트릭 이름과 연관된 레이블 조합에 따라 생성되는 시계열 수)가 기하급수적으로 늘어날 수 있기 때문에, 한계치가 명확하지 않은 레이블에 대한 메트릭은 다른 데이터 (로그 등)로 처리하는 것이 적합합니다.
이때, 쿠버네티스 매니페스트에서 사용하는 label이랑은 같은 이름이지만 전혀 다릅니다.!
discovered된 라벨은 프로메테우스가 쿠버네티스 API를 통해 자동으로 붙는 메타데이터 라벨이고, 쿠버네티스에서 붙는 라벨은 리소스 식별 용입니다.
부록 2) Prometheus 메트릭 수집을 통해 알 수 있는 것
메트릭을 이용하면 각 어플리케이션의 서브시스템에서 대기 시간과 처리하는 데이터 양을 추적하여 성능 저하의 원인이 무엇인지 확인할 수 있습니다.ex) HTTP 요청 횟수, 요청 처리하는데 걸린 시간 등등
- system metrics : 쿠버네티스 오브젝트에서 측정한 CPU, 메모리 사용량 등 시스템 메트릭
(쿠버네티스의 모든 컴포넌트는 프로메테우스의 metrics 형태로 엔드포인트를 제공하여 scrape 설정으로 메트릭 수집 가능)
- service metrics : HTTP 상태 코드 같은 서비스 상태 나타내는 메트릭
부록 3) Prometheus chunk 블록 병합
- --storage.tsdb.min-block-duration
- 하나의 블록에 저장된 데이터의 시간
- ex) 이 옵션이 2시간이면 블록 디렉터리에는 2시간 데이터 저장
- --storage.tsdb.max-block-duration
- 하나의 블록에 최대로 저장할 수 있는 시간
- ex) 이 옵션이 12h이면 하나의 청크 블록 디렉터리에는 최대 12시간 동안 보관 가능
부록 4) /metrics path exporter 노출
프로메테우스를 설치하면 쿠버네티스 시스템 컴포넌트들은 자동으로 /metrics를 제공하고 프로메테우스가 이를 감지하여 가져옵니다. 또한, 프로메테우스 오퍼레이터를 사용하면 기본적으로 여러 시스템 서비스들에 /metrics를 제공하도록 설정됩니다.
Prometheus Adapter
Prometheus 기반으로 쿠버네티스의 HPA 또는 KEDA 같은 오토스케일링 기능을 사용할 수 있도록 메트릭을 변환하여 제공하는 컴포넌트 입니다.
기존 메트릭 서버는 간단한 metrics-server를 사용하여 CPU, 메모리 등의 리소스 메트릭을 조회하여 HPA를 구성할 수 있습니다.
하지만, 어플리케이션별 커스텀 메트릭을 기준으로 오토스케일링 하려면 Prometheus에서 수집한 데이터를 쿠버네티스가 이해할 수 있는 형식으로 변환이 필요한데, 이 역할을 Prometheus adapter가 합니다.
metrics-server 아키텍처 및 특징
metrics-server는 CPU, 메모리와 같은 기본적인 리소스 메트릭을 제공하는 컴포넌트입니다.
kubectl top node, kubectl top pod 명령어를 실행할 때 사용됩니다.
HPA와 VPA가 기본적으로 참조하는 메트릭을 제공합니다.
kubelet에서 메트릭을 수집하여 쿠버네티스의 metrics.k8s.io API를 통해 노출됩니다.
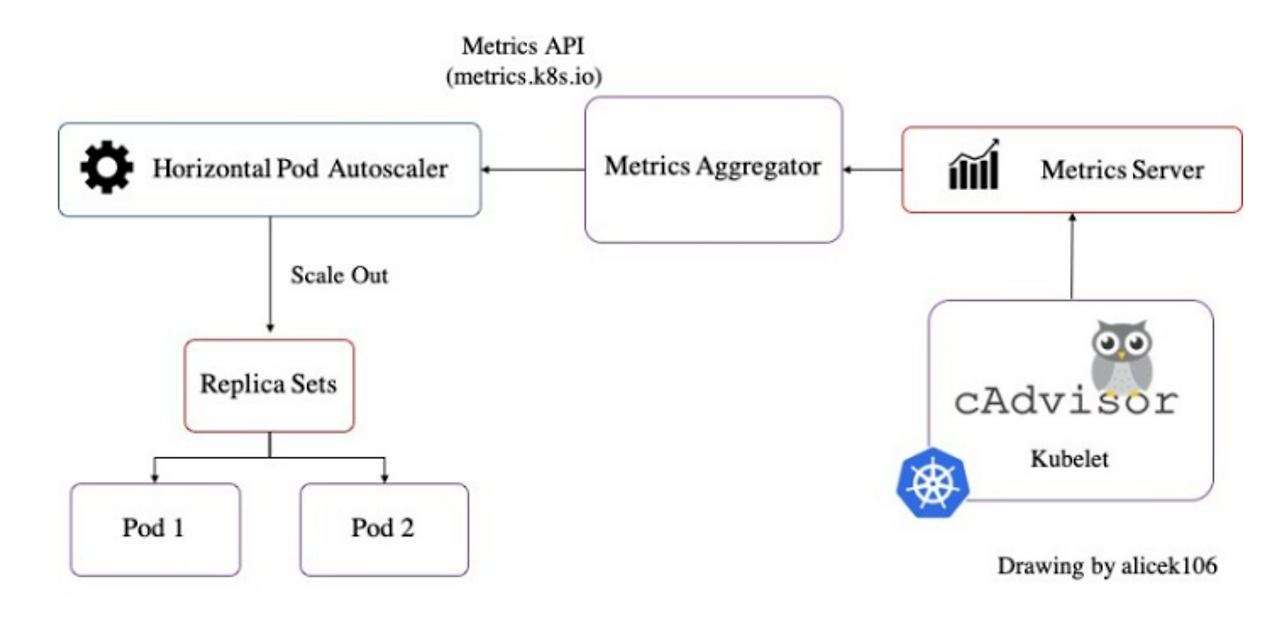
1) 각 노드의 kubelet이 cAdvisor를 통해 CPU, 메모리 사용량을 수집
2) Metrics Server가 각 노드의 kubelet에서 메트릭을 수집 (/stats/summary API 호출)
3) Metrics Server는 수집한 데이터를 Kubernetes API (metrics.k8s.io)로 노출
4) kubectl top pods, kubectl top nodes 등의 명령어가 metrics.k8s.io API를 호출하여 데이터를 가져옴
5) HPA는 Metrics Server의 데이터를 이용해 CPU/메모리 기반 자동 스케일링을 수행
# 노드 메트릭 확인
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
# 파드 메트릭 확인
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/namespaces/default/pods" | jq .
Prometheus adapter 아키텍처 및 특징
prometheus adapter는 프로메테우스에서 수집한 커스텀 메트릭을 쿠버네티스 HPA가 사용할 수 있도록 변환하는 컴포넌트입니다.
custom.metrics.k8s.io 또는 external.metrics.k8s.io API를 통해 프로메테우스의 데이터를 제공합니다.
HPA가 CPU, 메모리 외에 요청 수, 큐 길이, 사용자 정의 메트릭 등 다양한 기준으로 스케일링 할 수 있도록 도와줍니다.

1) Prometheus가 애플리케이션 및 Kubernetes에서 다양한 메트릭을 수집
2) Prometheus Adapter가 Prometheus API를 호출하여 특정 메트릭을 가져옴
3) Prometheus Adapter는 가져온 메트릭을 Kubernetes API (custom.metrics.k8s.io, external.metrics.k8s.io)로 변환하여 노출
4) HPA가 Prometheus Adapter를 호출하여, CPU/메모리 외에 사용자 정의 메트릭을 기반으로 오토스케일링을 수행
# 현재 custom.metrics.k8s.io가 제공하는 메트릭 확인
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
# 특정 네임스페이스에 Pod 기반 메트릭 조회
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests_per_second"'쿠버네티스' 카테고리의 다른 글
| [Observability] Prometheus 이해하기 (0) | 2025.03.01 |
|---|---|
| Istio (1) | 2023.04.21 |