Cloudnet AWES 5주차 스터디를 진행하며 정리한 글입니다.
이번 포스팅에서는 쿠버네티스에서 리소스 확장 방식 중 클러스터 노드의 수량을 조절하는 방식인 클러스터 오토스케일러(CAS) 및 노드에 비례하여 어플리케이션을 확장하는 클러스터 프로포셔널 오토스케일러(CPA)에 대해 소개하겠습니다.
Cluster Autoscaler (CAS)
Cluster Autoscaler(CAS)는 클러스터의 노드 개수를 자동으로 조절하는 역할입니다.
Pod가 스케줄링이 불가능할때는 노드를 추가하고, 일정기간 동안 사용하지 않는 노드는 제거하는 방식으로 동작합니다.
클라우드 프로바이더와는 연동하여 노드 풀을 확장하거나 축소합니다.
CAS의 동작원리
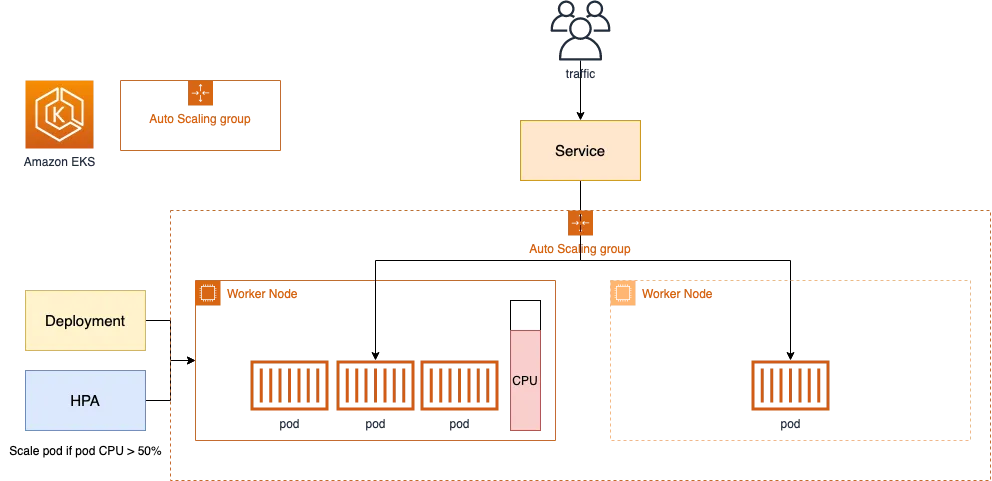
- Cluster Autoscale 동작을 하기 위한 cluster-autoscaler 파드(디플로이먼트)를 배치합니다.
- Cluster Autoscaler(CAS)는 pending 상태인 파드가 존재할 경우, 워커 노드를 스케일 아웃합니다.
- 특정 시간을 간격으로 사용률을 확인하여 스케일 인/아웃을 수행합니다. 그리고 AWS에서는 Auto Scaling Group(ASG)을 사용하여 Cluster Autoscaler를 적용합니다.
참고)
https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md
autoscaler/cluster-autoscaler/cloudprovider/aws/README.md at master · kubernetes/autoscaler
Autoscaling components for Kubernetes. Contribute to kubernetes/autoscaler development by creating an account on GitHub.
github.com
이제, CAS를 생성하고, 실제 노드 스케일인 아웃을 확인해보겠습니다.
CAS 실습
기본적으로 EKS에 이미 autoscaler에 대한 태그가 이미 들어가있습니다.
aws ec2 describe-instances --filters Name=tag:Name,Values=$CLUSTER_NAME-ng1-Node --query "Reservations[*].Instances[*].Tags[*]" --output yaml
...
- Key: k8s.io/cluster-autoscaler/myeks
Value: owned
- Key: k8s.io/cluster-autoscaler/enabled
Value: 'true'
...
현재 ASG (Auto Scaling Group) 정보를 확인하고, MaxSize를 수정하겠습니다. (3->6)
❯ aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-10caba54-2198-1778-c993-71dac20fafb0 | 3 | 3 | 3 |
+------------------------------------------------+----+----+----+
❯ export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
❯ aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 6
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-10caba54-2198-1778-c993-71dac20fafb0 | 3 | 6 | 3 |
+------------------------------------------------+----+----+----+q
그 후, Cluster Autoscaler를 배포하겠습니다.
처음에는 노드가 3대였지만, pending 상태의 파드가 발생하고 기존 노드에서 발생할 수 없는 경우, (CPU가 부족하여 노드에 스케줄이 불가능한 경우) ASG의 최대 노드 개수까지 노드를 확장합니다.
# CAS 배포
❯ curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
❯ sed -i -e "s|<YOUR CLUSTER NAME>|$CLUSTER_NAME|g" cluster-autoscaler-autodiscover.yaml
❯ kubectl apply -f cluster-autoscaler-autodiscover.yaml
serviceaccount/cluster-autoscaler created
clusterrole.rbac.authorization.k8s.io/cluster-autoscaler created
role.rbac.authorization.k8s.io/cluster-autoscaler created
clusterrolebinding.rbac.authorization.k8s.io/cluster-autoscaler created
rolebinding.rbac.authorization.k8s.io/cluster-autoscaler created
deployment.apps/cluster-autoscaler created
# 노드 상태 증가 확인 (3대)
❯ while true; do kubectl get node; echo "------------------------------" ; date ; sleep 1; done
------------------------------
Sun Mar 9 03:21:55 KST 2025
NAME STATUS ROLES AGE VERSION
ip-192-168-1-157.ap-northeast-2.compute.internal Ready <none> 10h v1.31.5-eks-5d632ec
ip-192-168-2-152.ap-northeast-2.compute.internal Ready <none> 10h v1.31.5-eks-5d632ec
ip-192-168-3-112.ap-northeast-2.compute.internal Ready <none> 10h v1.31.5-eks-5d632ec
------------------------------
❯ while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output text ; echo "------------------------------"; date; sleep 1; done
myeks-ng1-Node 192.168.3.112 running
operator-host 172.20.1.100 running
myeks-ng1-Node 192.168.1.157 running
myeks-ng1-Node 192.168.2.152 running
# Sample app 배포
❯ kubectl apply -f nginx.yaml
❯ kubectl scale --replicas=15 deployment/nginx-to-scaleout && date
# App Pending
❯ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-to-scaleout-7cfb655fb5-28gj2 1/1 Running 0 42s
nginx-to-scaleout-7cfb655fb5-2th9c 0/1 Pending 0 42s
nginx-to-scaleout-7cfb655fb5-4cpfx 1/1 Running 0 42s
nginx-to-scaleout-7cfb655fb5-79nwf 0/1 Pending 0 42s
nginx-to-scaleout-7cfb655fb5-bgwqr 0/1 Pending 0 42s
nginx-to-scaleout-7cfb655fb5-fjvgv 1/1 Running 0 42s
nginx-to-scaleout-7cfb655fb5-gm5pb 0/1 Pending 0 42s
nginx-to-scaleout-7cfb655fb5-hfksj 1/1 Running 0 64s
nginx-to-scaleout-7cfb655fb5-j82t8 1/1 Running 0 42s
nginx-to-scaleout-7cfb655fb5-kd7n2 1/1 Running 0 42s
nginx-to-scaleout-7cfb655fb5-kv8n6 0/1 Pending 0 42s
nginx-to-scaleout-7cfb655fb5-rnskv 1/1 Running 0 42s
nginx-to-scaleout-7cfb655fb5-v7zjb 0/1 Pending 0 42s
nginx-to-scaleout-7cfb655fb5-v9226 0/1 Pending 0 42s
nginx-to-scaleout-7cfb655fb5-vq7dc 1/1 Running 0 42s
# Pending된 Pod의 이벤트
# CPU가 부족하여 노드에 스케줄이 불가능
Warning FailedScheduling 19m default-scheduler 0/3 nodes are available: 3 Insufficient cpu. preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.
Normal TriggeredScaleUp 19m cluster-autoscaler pod triggered scale-up: [{eks-ng1-10caba54-2198-1778-c993-71dac20fafb0 3->6 (max: 6)}]
Warning FailedScheduling 18m default-scheduler 0/6 nodes are available: 2 node(s) had untolerated taint {node.kubernetes.io/not-ready: }, 4 Insufficient cpu. preemption: 0/6 nodes are available: 2 Preemption is not helpful for scheduling, 4 No preemption victims found for incoming pod.
Warning FailedScheduling 18m default-scheduler 0/6 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/not-ready: }, 5 Insufficient cpu. preemption: 0/6 nodes are available: 1 Preemption is not helpful for scheduling, 5 No preemption victims found for incoming pod.
Normal Scheduled 18m default-scheduler Successfully assigned default/nginx-to-scaleout-7cfb655fb5-kv8n6 to ip-192-168-3-96.ap-northeast-2.compute.internal
# 노드 상태 증가 확인 (6대)
❯ while true; do kubectl get node; echo "------------------------------" ; date ; sleep 1; done
------------------------------
Sun Mar 9 03:27:18 KST 2025
NAME STATUS ROLES AGE VERSION
ip-192-168-1-157.ap-northeast-2.compute.internal Ready <none> 10h v1.31.5-eks-5d632ec
ip-192-168-1-244.ap-northeast-2.compute.internal Ready <none> 2m9s v1.31.5-eks-5d632ec
ip-192-168-2-148.ap-northeast-2.compute.internal Ready <none> 2m4s v1.31.5-eks-5d632ec
ip-192-168-2-152.ap-northeast-2.compute.internal Ready <none> 10h v1.31.5-eks-5d632ec
ip-192-168-3-112.ap-northeast-2.compute.internal Ready <none> 10h v1.31.5-eks-5d632ec
ip-192-168-3-96.ap-northeast-2.compute.internal Ready <none> 2m3s v1.31.5-eks-5d632ec
❯ while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output text ; echo "------------------------------"; date; sleep 1; done
myeks-ng1-Node 192.168.3.112 running
myeks-ng1-Node 192.168.3.96 running
operator-host 172.20.1.100 running
myeks-ng1-Node 192.168.1.157 running
myeks-ng1-Node 192.168.1.244 running
myeks-ng1-Node 192.168.2.152 running
myeks-ng1-Node 192.168.2.148 running
# App Running (노드 증가 후)
❯ kubectl get pod ○ myeks 03:25:49
NAME READY STATUS RESTARTS AGE
nginx-to-scaleout-7cfb655fb5-28gj2 1/1 Running 0 4m37s
nginx-to-scaleout-7cfb655fb5-2th9c 1/1 Running 0 4m37s
nginx-to-scaleout-7cfb655fb5-4cpfx 1/1 Running 0 4m37s
nginx-to-scaleout-7cfb655fb5-79nwf 1/1 Running 0 4m37s
nginx-to-scaleout-7cfb655fb5-bgwqr 1/1 Running 0 4m37s
nginx-to-scaleout-7cfb655fb5-fjvgv 1/1 Running 0 4m37s
nginx-to-scaleout-7cfb655fb5-gm5pb 1/1 Running 0 4m37s
nginx-to-scaleout-7cfb655fb5-hfksj 1/1 Running 0 4m59s
nginx-to-scaleout-7cfb655fb5-j82t8 1/1 Running 0 4m37s
nginx-to-scaleout-7cfb655fb5-kd7n2 1/1 Running 0 4m37s
nginx-to-scaleout-7cfb655fb5-kv8n6 1/1 Running 0 4m37s
nginx-to-scaleout-7cfb655fb5-rnskv 1/1 Running 0 4m37s
nginx-to-scaleout-7cfb655fb5-v7zjb 1/1 Running 0 4m37s
nginx-to-scaleout-7cfb655fb5-v9226 1/1 Running 0 4m37s
nginx-to-scaleout-7cfb655fb5-vq7dc 1/1 Running 0 4m37s
myeks-ng1-Node 192.168.3.112 running
myeks-ng1-Node 192.168.3.96 running
operator-host 172.20.1.100 running
myeks-ng1-Node 192.168.1.157 running
myeks-ng1-Node 192.168.1.244 running
myeks-ng1-Node 192.168.2.152 running
myeks-ng1-Node 192.168.2.148 running
eks-nodeviewer로 현재 노드가 얼만큼의 리소스를 사용하고 있는지 확인할 수 있습니다.
또한, cloud-autoscaler 파드가 기존과 달리 scale up, scale down 하는 것에 대한 로그도 남습니다.
# eks-nodeviewer
6 nodes ( 9200m/11580m) 79.4% cpu ████████████████████████████████░░░░░░░░ $0.312/hour | $227.
10020Mi/20187168Ki 50.8% memory ████████████████████░░░░░░░░░░░░░░░░░░░░
55 pods (0 pending 55 running 55 bound)
ip-192-168-1-157.ap-northeast-2.compute.internal cpu ██████████████████████████████░░░░░ 87% (12
memory ████████████████████████░░░░░░░░░░░ 70%
ip-192-168-2-152.ap-northeast-2.compute.internal cpu ████████████████████████████████░░░ 90% (12
memory ████████████████████░░░░░░░░░░░░░░░ 58%
ip-192-168-3-112.ap-northeast-2.compute.internal cpu ████████████████████████████████░░░ 90% (12
memory ████████████████████░░░░░░░░░░░░░░░ 58%
ip-192-168-1-244.ap-northeast-2.compute.internal cpu ██████████████████████████████░░░░░ 87% (7 p
memory ██████████████████░░░░░░░░░░░░░░░░░ 50%
••
# cluster autoscaler 로그 (위의 경우와 같이 스케일 업이 아니라 스케일 다운 시)
I0308 18:38:42.905496 1 klogx.go:87] Node ip-192-168-1-244.ap-northeast-2.compute.internal - cpu utilization 0.093264
I0308 18:38:42.905565 1 klogx.go:87] Node ip-192-168-2-148.ap-northeast-2.compute.internal - cpu utilization 0.093264
I0308 18:38:42.905623 1 eligibility.go:144] Node ip-192-168-1-157.ap-northeast-2.compute.internal is not suitable for removal - cpu utilization too big (0.870466)
I0308 18:38:42.905662 1 eligibility.go:102] Scale-down calculation: ignoring 3 nodes unremovable in the last 5m0s
I0308 18:38:42.905729 1 nodes.go:84] ip-192-168-2-148.ap-northeast-2.compute.internal is unneeded since 2025-03-08 18:38:12.768345463 +0000 UTC m=+1038.911032291 duration 30.135846773s
I0308 18:38:42.905773 1 nodes.go:84] ip-192-168-1-244.ap-northeast-2.compute.internal is unneeded since 2025-03-08 18:38:12.768345463 +0000 UTC m=+1038.911032291 duration 30.135846773s
I0308 18:38:42.905817 1 static_autoscaler.go:589] Scale down status: lastScaleUpTime=2025-03-08 18:24:18.906755892 +0000 UTC m=+205.049442622 lastScaleDownDeleteTime=2025-03-08 17:20:58.114311482 +0000 UTC m=-3595.743001765 lastScaleDownFailTime=2025-03-08 17:20:58.114311482 +0000 UTC m=-3595.743001765 scaleDownForbidden=false scaleDownInCooldown=false
I0308 18:38:42.905857 1 static_autoscaler.go:598] Starting scale down
I0308 18:38:42.905886 1 nodes.go:123] ip-192-168-1-244.ap-northeast-2.compute.internal was unneeded for 30.135846773s
I0308 18:38:42.905910 1 nodes.go:123] ip-192-168-2-148.ap-northeast-2.compute.internal was unneeded for 30.135846773s
만약 이벤트가 궁금하다면 CloudTrail에 CreateFleet 이벤트를 확인할 수 있습니다.
{
"Events": [
{
"EventId": "3618e718-8945-491c-9c80-6d8545431152",
"EventName": "CreateFleet",
"ReadOnly": "false",
"EventTime": "2025-03-09T03:24:25+09:00",
"EventSource": "ec2.amazonaws.com",
"Username": "AutoScaling",
"Resources": [],
"CloudTrailEvent": "{\"eventVersion\":\"1.10\",\"userIdentity\":{\"type\":\"AssumedRole\",\"principalId\":\"AROA5WLTS2JVP22K5MS7K:AutoScaling\",\"arn\":\"arn:aws:sts::941377114730:assumed-role/AWSServiceRoleForAutoScaling/AutoScaling\",\"accountId\":\"941377114730\",\"sessionContext\":{\"sessionIssuer\":{\"type\":\"Role\",\"principalId\":\"AROA5WLTS2JVP22K5MS7K\",\"arn\":\"arn:aws:iam::941377114730:role/aws-service-role/autoscaling.amazonaws.com/AWSServiceRoleForAutoScaling\",\"accountId\":\"941377114730\",\"userName\":\"AWSServiceRoleForAutoScaling\"},\ ...
Cluster Proportional Autoscaler (CPA)
노드 수 증가에 비례하여 성능 처리가 필요한 어플리케이션을 수평으로 자동 확장하는 역할입니다.
노드의 수가 증가함에 따라 부하를 많이 받는 CoreDNS, kube-proxy 같은 특정 Kubernetes 컴포넌트의 개수를 자동 조절합니다.
CPU, 메모리 등의 Metric server를 통한 리소스를 기반으로 하는 것이 아니라 클러스터 크기(노드 수, Pod 수, CPU 코어 수)를 기준으로 특정 pod의 개수를 조정합니다.
CPA의 동작원리

1. 설정한 비율(proportional scaling)에 따라 특정 시스템 컴포넌트의 개수를 자동 조정
2. ConfigMap을 통해 스케일링 정책을 정의하고, 이에 따라 특정 Deployment나 DaemonSet의 replica 개수를 조정
CPA 실습
cluster-proportional-autoscaler Helm 차트를 등록해줍니다.
그 후, CPA 규칙을 설정하고, helm 차트를 배포합니다. helm 차트에는 기본적인 CPA value 규칙이 없는데, 따라서 별도의 설정을 하지 않고 배포를 하면 배포가 실패하게 됩니다.
하지만, 특정 파드에 대한 CPA 규칙을 적용하고 배포하게 되면, cluster-proportional-autoscaler는 정상적으로 배포 됩니다.
아래 상황에서도, nginx-deployment에 대해, 노드가 1개라면 nginx pod를 1개, 노드가 2개라면 nginx pod를 2개 배포하도록 CPA 정책을 설정하였습니다.
그랬더니 기존에 nginx-deployment 파드는 1대만 실행되고 있었는데, cluster-proportional-autoscaler가 배포됨에 따라 노드가 3개라 nginx pod도 3개로 증가한 것을 확인할 수 있습니다.
# 차트 추가
❯ helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler
❯ helm repo update
# CPA 배포 실패
❯ helm upgrade --install cluster-proportional-autoscaler cluster-proportional-autoscaler/cluster-proportional-autoscaler
helm upgrade --install cluster-proportional-autoscaler cluster-proportional-autoscaler/cluster-proportional-autoscaler
Release "cluster-proportional-autoscaler" does not exist. Installing it now.
Error: execution error at (cluster-proportional-autoscaler/templates/deployment.yaml:3:3): options.target must be one of deployment, replicationcontroller, or replicaset
# 테스트용 nginx 배포
❯ kubectl apply -f cpa-nginx.yaml
# Pod 확인
Every 2.0s: kubectl get pod
in 1.009s (0)
NAME READY STATUS RESTARTS AGE
nginx-deployment-7fbd95ff6c-9klxz 1/1 Running 0 2m8s
# CPA 규칙 설정
❯ cat <<EOF > cpa-values.yaml
config:
ladder:
nodesToReplicas: # 노드와 파드의 비율 N : N
- [1, 1]
- [2, 2]
- [3, 3]
- [4, 3]
- [5, 5]
options:
namespace: default
target: "deployment/nginx-deployment"
EOF
❯ kubectl describe cm cluster-proportional-autoscaler
# 테스트용 nginx를 타겟으로 한 CPA 규칙 설정 후 배포 -> 배포 성공
❯ helm upgrade --install cluster-proportional-autoscaler -f cpa-values.yaml cluster-proportional-autoscaler/cluster-proportional-autoscaler
# Pod 확인
Every 2.0s: kubectl get pod yujiyeon-ui-MacBookPro.local: 03:59:40
in 1.045s (0)
NAME READY STATUS RESTARTS AGE
cluster-proportional-autoscaler-7c8546855d-k5v87 1/1 Running 0 57s
nginx-deployment-7fbd95ff6c-9klxz 1/1 Running 0 2m39s
nginx-deployment-7fbd95ff6c-cm5sc 1/1 Running 0 52s
nginx-deployment-7fbd95ff6c-dkdrf 1/1 Running 0 52s
실제로, cluster-proportional-autoscaler pod의 로그를 확인했을 때도, 해당 파드가 nginx 파드를 1 -> 3 으로 증가시킨 것을 확인할 수 있습니다.
❯ kubectl logs cluster-proportional-autoscaler-7c8546855d-k5v87
I0308 18:58:48.707009 1 autoscaler.go:49] Scaling Namespace: default, Target: deployment/nginx-deployment
I0308 18:58:48.964935 1 ladder_controller.go:72] Detected ConfigMap version change (old: new: 198597) - rebuilding lookup entries
I0308 18:58:48.974049 1 k8sclient.go:273] Cluster status: SchedulableNodes[3], SchedulableCores[6]
I0308 18:58:48.974068 1 k8sclient.go:274] Replicas are not as expected : updating replicas from 1 to 3
++ 참고로, CPU/Memory 기반 정책도 다음과 같이 설정할 수 있다고 합니다.
"coresToReplicas":
[
[ 1, 1 ],
[ 64, 3 ],
[ 512, 5 ],
[ 1024, 7 ],
[ 2048, 10 ],
[ 4096, 15 ]
],
https://github.com/kubernetes-sigs/cluster-proportional-autoscaler/tree/master/examples
cluster-proportional-autoscaler/examples at master · kubernetes-sigs/cluster-proportional-autoscaler
Kubernetes Cluster Proportional Autoscaler Container - kubernetes-sigs/cluster-proportional-autoscaler
github.com
'스터디 > AEWS' 카테고리의 다른 글
| [AEWS] 6주차 Kubeconfig 이해하기 및 CSR을 통한 신규 인증서 발급 (0) | 2025.03.11 |
|---|---|
| [AEWS] 5주차 쿠버네티스 오토스케일링 이해하기 - Karpenter (0) | 2025.03.09 |
| [AEWS] 5주차 쿠버네티스 오토스케일링 이해하기 - 수직 확장 (VPA) (0) | 2025.03.09 |
| [AEWS] 5주차 쿠버네티스 오토스케일링 이해하기 - 수평 확장 (HPA, KEDA) (0) | 2025.03.08 |
| [AEWS] 4주차 Grafana 이해하기 (0) | 2025.03.02 |