Cloudnet AWES 5주차 스터디를 진행하며 정리한 글입니다.
이번 포스팅에서는 쿠버네티스에서 리소스 확장 기술에 대해 설명하고, 확장 방식에 따라 수평적으로 Pod 대수의 오토스케일링이 일어나는 기술인 HPA와 KEDA에 대해 알아보겠습니다.
쿠버네티스 리소스 확장 기술

쿠버네티스 환경에서 어플리케이션을 배포하여 운영하다 보면 리소스가 부족하여 확장이 필요한 경우가 발생하곤 합니다.
이 때 다양한 방식으로 리소스를 탄력적으로 확장할 수 있습니다.
1. Application Tuning (애플리케이션 튜닝)
- 컨테이너 내에서 실행되는 프로세스의 설정을 조정하여 성능을 최적화하는 방식입니다.
- 컨테이너 자체의 리소스는 그대로 유지되며, 내부 프로세스만 튜닝됩니다.
- ex) 스레드 수, JVM 힙 크기 조정 등을 변경

2. Vertical Pod Autoscaler (VPA)
- Pod의 CPU 및 메모리 할당량을 조정하여 확장하는 방식입니다.
- 단일 Pod의 리소스를 조정하여 스케일업/다운합니다.
- 기존 Pod를 삭제하고 새로운 리소스 값을 반영한 Pod를 다시 생성하는 과정이 필요합니다.
3. Horizontal Pod Autoscaler (HPA)
- Pod 개수를 동적으로 조정하는 방식입니다.
- 트래픽이 증가하면 새로운 Pod를 생성하고, 감소하면 Pod 개수를 줄입니다.
- CPU, 메모리, 사용자 정의 메트릭(Custom Metrics) 등을 기반으로 확장합니다.
4. Cluster Autoscaler (CAS)
- 클러스터의 노드 수를 조정하는 방식입니다.
- Pod가 스케줄링될 공간이 부족할 경우 노드를 추가하고, 불필요하면 노드를 삭제합니다.
- 물리 환경 대신 유연한 자원 사용이 가능한 클라우드 환경에서 주로 동작합니다.
HPA 실습
HPA (Horizontal Pod Autoscaler)
HPA는 CPU, 메모리 등의 리소스 사용량을 기반으로 Pod 개수를 조정하는 방식입니다.
애플리케이션의 CPU, 메모리 사용량 또는 커스텀 메트릭(Custom Metrics) 기반으로 Pod 개수를 동적으로 늘리거나 줄이는 역할을 합니다.
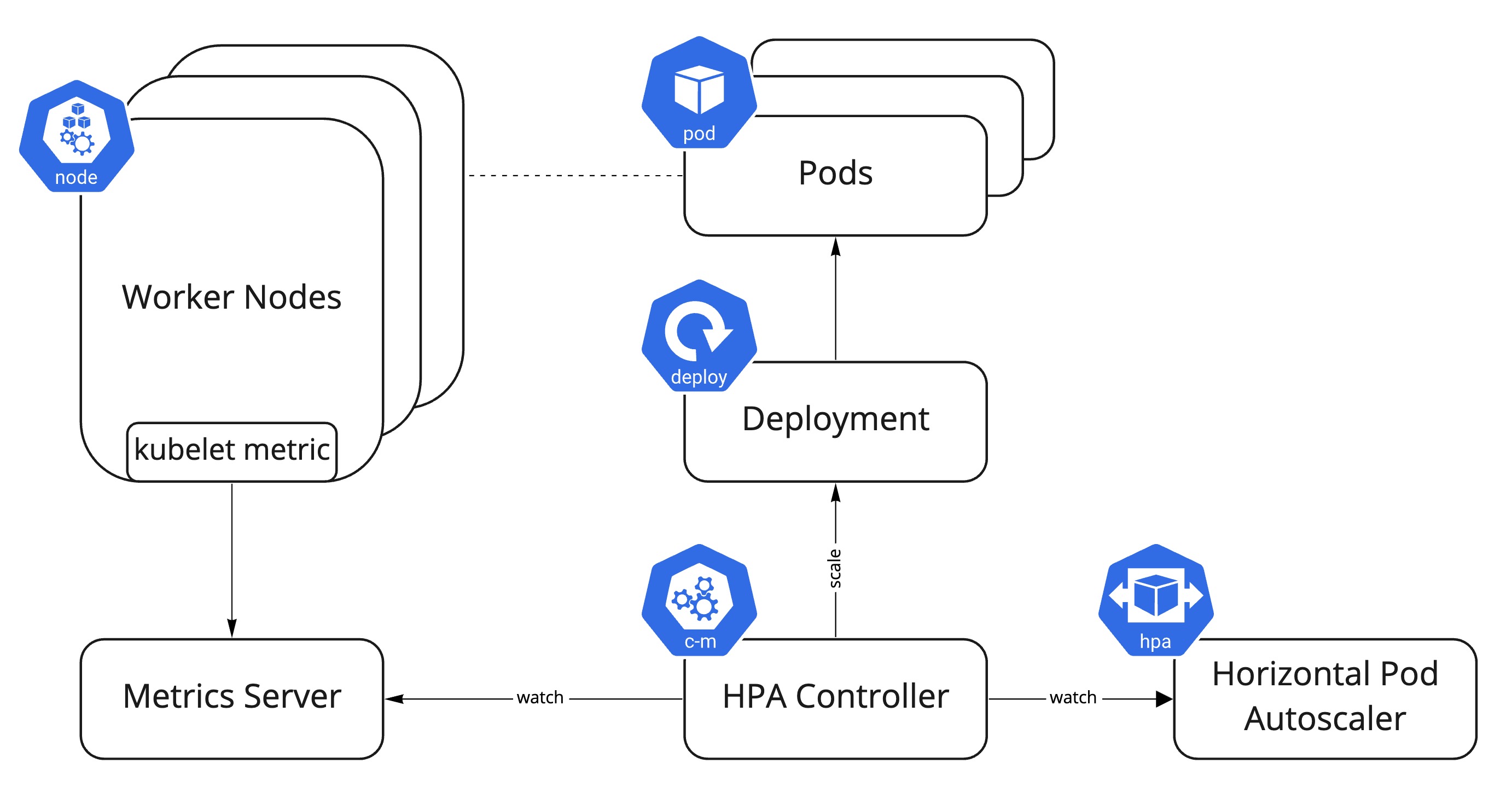
HPA의 동작원리
- HPA는 Kubernetes API를 통해 Pod의 리소스 사용량을 주기적으로 조회
- 사용자가 설정한 CPU, 메모리, 또는 Custom Metrics 기준과 비교
- Pod의 평균 사용량이 기준치를 초과하면 Pod 개수를 추가 (Scale-out) /기준보다 사용량이 낮아지면 Pod 개수를 감소(Scale-in)
테스트용 서비스를 배포하고, HPA 정책 생성하겠습니다.
❯ cat << EOF > php-apache.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
EOF
kubectl apply -f php-apache.yaml
# HPA 배포 전
❯ watch -d 'kubectl get hpa,pod;echo;kubectl top pod;echo;kubectl top node'
NAME READY STATUS RESTARTS AGE
pod/php-apache-d87b7ff46-zt5ds 1/1 Running 0 5m27s
NAME CPU(cores) MEMORY(bytes)
php-apache-d87b7ff46-zt5ds 1m 8Mi
NAME CPU(cores) CPU(%) MEMORY(by
tes) MEMORY(%)
ip-192-168-1-157.ap-northeast-2.compute.internal 55m 2% 632Mi
19%
ip-192-168-2-152.ap-northeast-2.compute.internal 119m 6% 869Mi
26%
ip-192-168-3-112.ap-northeast-2.compute.internal 146m 7% 949Mi
28%
# HPA 배포
❯ cat <<EOF | kubectl apply -f -
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache # php-apache deployement에 대해서
minReplicas: 1 # 파드 최대 1대 까지 줄일 수 있음
maxReplicas: 10 # 최대 10대 까지 늘릴 수 있음
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 50 # CPU 활용률 50% 이상인 경우
type: Utilization
EOF
# 다음 명령어도 위와 동일한 수행을 합니다.
❯ kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
horizontalpodautoscaler.autoscaling/php-apache autoscaled
# HPA 배포 후 리소스가 생성된 것을 확인
❯ watch -d 'kubectl get hpa,pod;echo;kubectl top pod;echo;kubectl top node'
NAME REFERENCE TARGETS
MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/php-apache Deployment/php-apache cpu: <unk
nown>/50% 1 10 0 6s
NAME READY STATUS RESTARTS AGE
pod/php-apache-d87b7ff46-zt5ds 1/1 Running 0 7m49s
NAME CPU(cores) MEMORY(bytes)
php-apache-d87b7ff46-zt5ds 1m 8Mi
NAME CPU(cores) CPU(%) MEMORY(by
tes) MEMORY(%)
ip-192-168-1-157.ap-northeast-2.compute.internal 56m 2% 633Mi
19%
ip-192-168-2-152.ap-northeast-2.compute.internal 148m 7% 860Mi
26%
ip-192-168-3-112.ap-northeast-2.compute.internal 157m 8% 952Mi
29%
부하 발생 후 오토 스케일링이 되는지 확인하겠습니다.
부하 발생 시 HPA 동작을 확인합니다.
## 부하 발생 전
# HPA 적용 확인
❯ watch -d 'kubectl get hpa,pod;echo;kubectl top pod;echo;kubectl top node'
NAME REFERENCE TARGETS
MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/php-apache Deployment/php-apache cpu: 0%/5
0% 1 10 1 7m44s
NAME READY STATUS RESTARTS AGE
pod/php-apache-d87b7ff46-zt5ds 1/1 Running 0 15m
NAME CPU(cores) MEMORY(bytes)
php-apache-d87b7ff46-zt5ds 1m 9Mi
NAME CPU(cores) CPU(%) MEMORY(by
tes) MEMORY(%)
ip-192-168-1-157.ap-northeast-2.compute.internal 79m 4% 636Mi
19%
ip-192-168-2-152.ap-northeast-2.compute.internal 275m 14% 868Mi
26%
ip-192-168-3-112.ap-northeast-2.compute.internal 210m 10% 950Mi
28%
# Pod 내부 자원 사용량 확인
❯ kubectl exec -it deploy/php-apache -- top
top - 09:00:38 up 1:30, 0 users, load average: 0.05, 0.06, 0.07
Tasks: 7 total, 1 running, 6 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.0 us, 1.3 sy, 0.0 ni, 96.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 3919540 total, 2846560 used, 1072980 free, 3172 buffers
KiB Swap: 0 total, 0 used, 0 free. 2046448 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 166268 19320 14048 S 0.0 0.5 0:00.11 apache2
8 www-data 20 0 166348 10204 4868 S 0.0 0.3 0:00.08 apache2
9 www-data 20 0 166292 7116 1836 S 0.0 0.2 0:00.00 apache2
10 www-data 20 0 166292 7116 1836 S 0.0 0.2 0:00.00 apache2
11 www-data 20 0 166292 7116 1836 S 0.0 0.2 0:00.00 apache2
12 www-data 20 0 166292 7116 1836 S 0.0 0.2 0:00.00 apache2
19 root 20 0 21920 2432 2100 R 0.0 0.1 0:00.04 top
# 부하 발생
❯ kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
If you don't see a command prompt, try pressing enter.
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!O
## 부하 발생 후
# replicas 수 증가
❯ watch -d 'kubectl get hpa,pod;echo;kubectl top pod;echo;kubectl top node'
NAME REFERENCE TARGETS
MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/php-apache Deployment/php-apache cpu: 52%/
50% 1 10 6 10m
NAME READY STATUS RESTARTS AGE
pod/load-generator 1/1 Running 0 2m9s
pod/php-apache-d87b7ff46-djdb6 1/1 Running 0 90s
pod/php-apache-d87b7ff46-ldd5x 1/1 Running 0 30s
pod/php-apache-d87b7ff46-tzwpm 1/1 Running 0 90s
pod/php-apache-d87b7ff46-vh9vj 1/1 Running 0 90s
pod/php-apache-d87b7ff46-zcvfb 1/1 Running 0 75s
pod/php-apache-d87b7ff46-zt5ds 1/1 Running 0 18m
NAME CPU(cores) MEMORY(bytes)
load-generator 10m 0Mi
php-apache-d87b7ff46-djdb6 100m 11Mi
php-apache-d87b7ff46-ldd5x 134m 10Mi
php-apache-d87b7ff46-tzwpm 109m 11Mi
php-apache-d87b7ff46-vh9vj 84m 11Mi
# Pod 내부 자원 사용량 증가
❯ kubectl exec -it deploy/php-apache -- top
top - 09:03:15 up 1:33, 0 users, load average: 0.15, 0.11, 0.09
KiB Mem: 3919540 total, 2866356 used, 1053184 free, 3172 buffers
KiB Swap: 0 total, 0 used, 0 free. 2047604 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10 www-data 20 0 166348 10976 5604 S 3.0 0.3 0:04.77 apache2
8 www-data 20 0 166348 10976 5604 S 2.7 0.3 0:04.83 apache2
9 www-data 20 0 166348 10976 5604 S 2.7 0.3 0:04.78 apache2
26 www-data 20 0 166348 10976 5604 S 2.7 0.3 0:04.60 apache2
1 root 20 0 166268 19320 14048 S 0.0 0.5 0:00.11 apache2
11 www-data 20 0 166348 10976 5604 S 0.0 0.3 0:04.66 apache2
12 www-data 20 0 166348 10976 5604 S 0.0 0.3 0:04.71 apache2
19 root 20 0 21920 2432 2100 R 0.0 0.1 0:00.07 top
실습 준비하며 배포한 Grafana 대시보드에서도 Target 메트릭 보다 Current 메트릭이 증가하여 해당 시점부터 replicas가 증가한 것을 확인할 수 있습니다.

Prometheus 대시보드에서도 HPA replicas가 증가한 것을 확인할 수 있습니다.

다음으로는 기본 리소스 사용률이 아닌 커스텀 메트릭 기반으로 HPA를 동작시켜보겠습니다.
커스텀 메트릭과 관련된 프로메테우스 Adapter에 대한 설명은 저의 이전 포스팅을 참고해주시길 부탁드립니다.
https://hellouz818.tistory.com/38
[Observability] Prometheus 이해하기 2 + Prometheus adapter
Prometheus의 라이프사이클1) 메트릭을 수집하고, 시계열로 저장합니다.2) 메트릭을 측정하고, 리소스를 오토스케일링 처리합니다.3) 변경된 리소스를 자동으로 디스커버리합니다.4) HPA와 연계하여
hellouz818.tistory.com
커스텀 메트릭으로 HPA를 작동시키기 위해 Prometheus Adapter를 설치하겠습니다.
# proemetheus adapter 설치
❯ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
❯ helm install prometheus-adapter prometheus-community/prometheus-adapter \
--namespace monitoring
...
# chart 배포 시 custom 메트릭 api를 사용할 수 있다고 확인할 수 있습니다.
In a few minutes you should be able to list metrics using the following command(s):
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1
❯ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1
{"kind":"APIResourceList","apiVersion":"v1","groupVersion":"custom.metrics.k8s.io/v1beta1","resources":[]}
그렇다면, Custom Metrics 중 지난 번 실습 때 사용하였던 nginx 파드에 대해 nginx_http_reqeust_total 메트릭을 사용하여 커스텀 메트릭에 대한 HPA를 실행해보겠습니다.
Prometheus Adapter에 수집할 커스텀 메트릭에 대한 규칙을 작성한 후 API 호출을 해봅니다.
# prometheus adapter에 규칙 추가
prometheus:
# Value is templated
url: http://kube-prometheus-stack-prometheus.monitoring.svc
port: 9090
path: ""
rules:
default: true
custom:
- seriesQuery: '{__name__=~"^nginx_http_requests_total.*", namespace!=""}'
seriesFilters: []
resources:
template: <<.Resource>>
overrides:
pod:
resource: "pod"
namespace:
resource: "namespace"
service:
resource: "service"
name:
matches: ""
as: "nginx_http_requests_total_rate"
metricsQuery: "sum(rate(nginx_http_requests_total[1m])) by (pod)"
# 메트릭 확인
❯ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/nginx_http_requests_total_rate" | jq
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "nginx-7ff5bc99dd-fwmtm",
"apiVersion": "/v1"
},
"metricName": "nginx_http_requests_total_rate",
"timestamp": "2025-03-08T14:41:42Z",
"value": "740m",
"selector": null
}
]
}
이 때, HPA를 external 타입으로 생성했을 때는 external 메트릭으로 가져오는 반면, 해당 메트릭은 커스텀 메트릭이므로 메트릭 타입을 변경해줍니다.
# 처음 시도한 HPA
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-custom-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
minReplicas: 1
maxReplicas: 5
metrics:
- type: External
external:
metric:
name: nginx_http_requests_total_rate
target:
type: AverageValue
averageValue: 1
# HPA 이벤트 에러로그
# External이 아닌 Custom 메트릭으로 변경 필요
unable to fetch metrics from external metrics API: the server could not find
the metric nginx_http_requests_total for namespaces
# 변경한 HPA
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-custom-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
minReplicas: 1
maxReplicas: 5
metrics:
- type: Pods
pods:
metric:
name: nginx_http_requests_total_rate
target:
type: AverageValue
averageValue: 1
❯ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-custom-hpa Deployment/nginx 680m/1 1 5 1 46m
php-apache Deployment/php-apache cpu: 0%/50% 1 10 1 5h54m
참고로, HPA의 metrics 필드에서 사용할 수 있는 메트릭 유형은 다음과 같습니다.
- Resource : Pod의 CPU/Memory 사용량 기반 (cpu, memory)
- Pods : 특정 Pod의 Custom metrics 기반 (request_per_second)
- Objects : 특정 Kubernetes 오브젝트 기반 (active_connections)
- Externals : Kubernetes 외부 서비스의 메트릭 기반 (aws_sqs_queue_length)
HPA가 잘 등록된 것을 알 수 있습니다.
기존에 Prometheus는 다음과 같았는데, nginx를 많이 호출해보며 변화를 살펴보겠습니다.
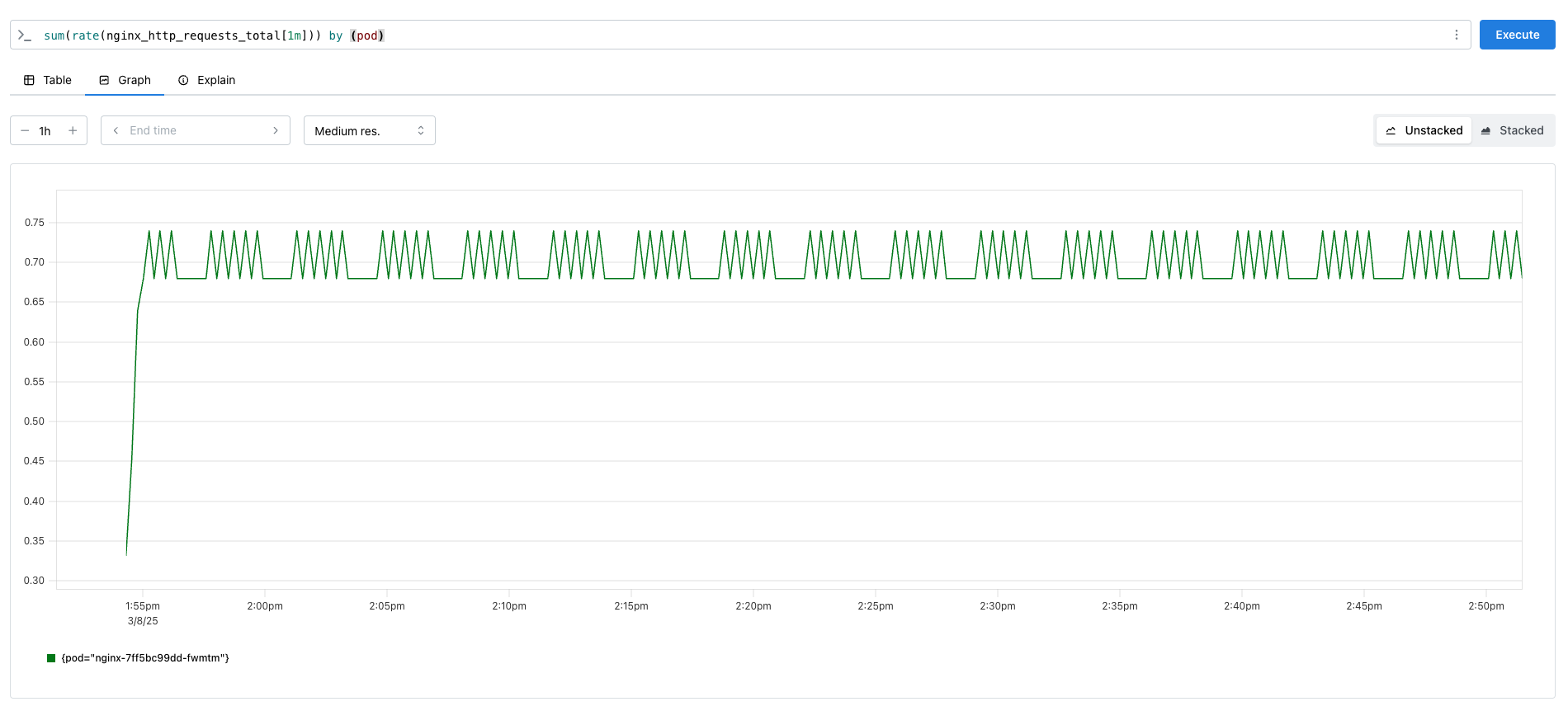
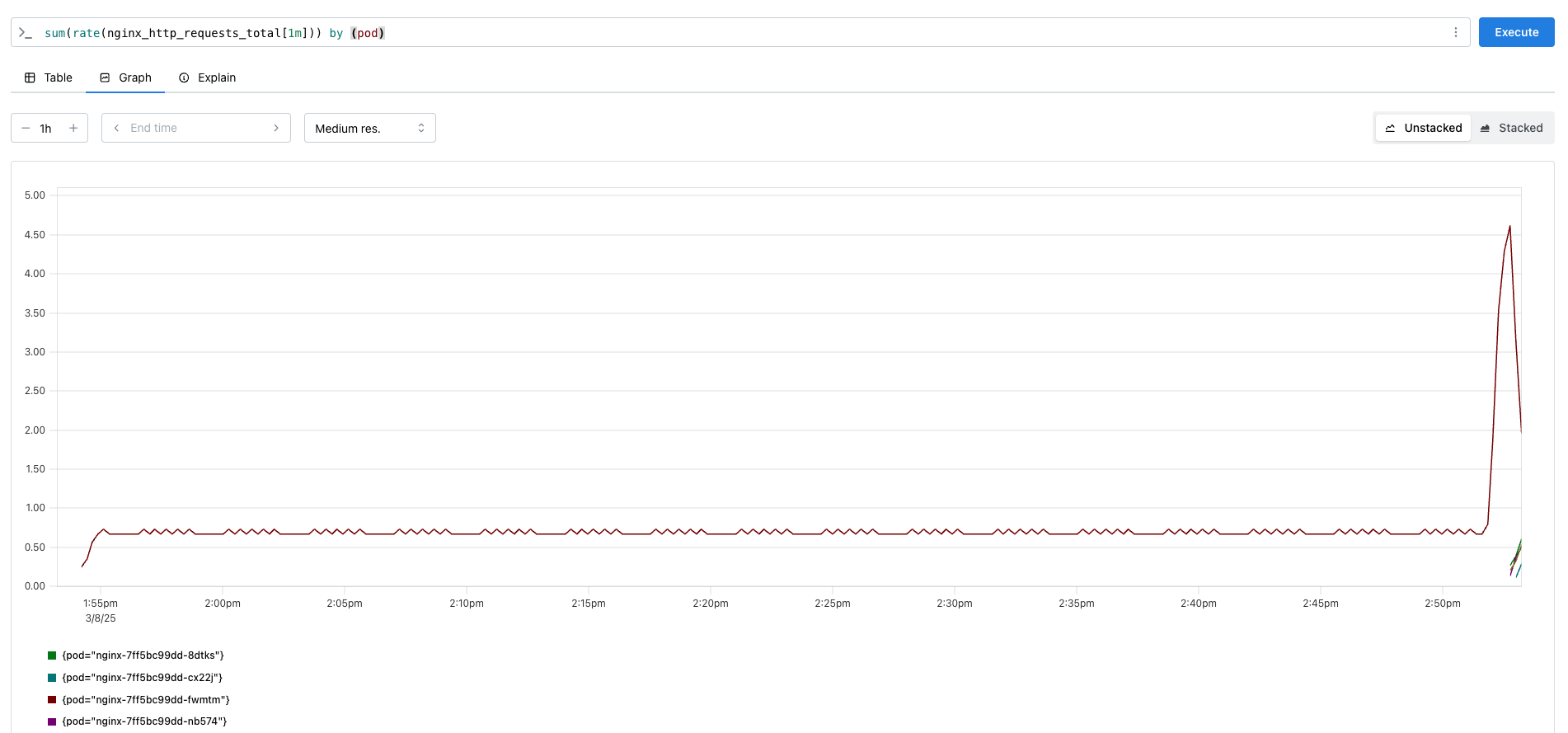
호출 수에 따라 호출 메트릭이 증가하였고, 그에 따라 pod replicas 수도 증가한 것을 확인할 수 있었습니다.
❯ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-custom-hpa Deployment/nginx 1613m/1 1 5 4 52m
php-apache Deployment/php-apache cpu: 0%/50% 1 10 1 6h
KEDA 실습
KEDA (Kubernetes Event-Driven Autoscaler)
KEDA는 이벤트 기반으로 Pod를 오토스케일링하는 오픈소스입니다.
기본적으로 HPA를 확장한 형태이며, CPU나 메모리 같은 전통적인 메트릭이 아닌, 이벤트를 기반으로 Pod를 확장하는 기능을 제공합니다. 따라서, HPA를 활용하지만, HPA가 지원하지 않는 다양한 이벤트 소스를 기반으로 Pod를 자동 확장할 수 있습니다.
KEDA는 특정 이벤트가 발생하면 이를 감지하여 Pod의 개수를 조정합니다.

KEDA의 구성요소
1) Metrics Adapter
- KEDA는 Kubernetes의 Metrics Server 역할을 수행하며, HPA가 이해할 수 있는 External Metrics를 제공합니다.
- CPU, 메모리가 아닌 Kafka 메시지 수, RabbitMQ 큐 길이, Prometheus 알람 같은 다양한 데이터를 Kubernetes Metrics API에 전달하여 HPA가 이를 기반으로 Pod를 확장할 수 있도록 합니다.
2) Controller (KEDA Operator)
- Kubernetes에서 실행되는 KEDA의 핵심 컨트롤러입니다.
- ScaledObject 및 ScaledJob 감지합니다.
- 이벤트 소스에서 메트릭을 수집합니다.
- 수집된 데이터 기반으로 HPA를 생성하거나 Pod 개수를 직접 조정하고, 필요 시 Pod 개수를 0까지 축소합니다.
3) Scalers
- 다양한 이벤트 소스에서 데이터를 수집하고, Pod 확장 필요 여부를 결정하는 역할을 합니다.
- Scaler 종류:
- Message Queue: Kafka, RabbitMQ, AWS SQS, Azure Queue
- Database: MySQL, PostgreSQL, Redis Streams
- Monitoring System: Prometheus, Datadog
- Cloud Services: AWS Kinesis, Azure Blob Storage, Google Pub/Sub 등
4) Admission Webhooks
- Kubernetes의 Admission Controller 기능을 활용하여 KEDA 설정을 자동으로 검증하는 역할을 합니다.
- 잘못된 ScaledObject 설정이 적용되지 않도록 차단하고, 하나의 Deployment에 여러 개의 ScaledObject가 설정되는 것을 방지합니다.
5) ScaledObject
- HPA를 생성하고 이벤트 기반으로 확장할 리소스를 정의하는 CRD
- Pod 개수를 자동으로 확장하고 싶은 Deployment 또는 StatefulSet에 대해 적용합니다.
6) ScaledJob
- Job 리소스를 이벤트 기반으로 자동 확장할 때 사용
- ScaledObject는 Deployment와 같이 항상 실행되는 애플리케이션에 적합하지만, ScaledJob은 일정한 이벤트가 발생할 때 일시적인 Job을 실행하는 경우에 적합합니다.
KEDA의 동작원리
- 사용자가 ScaledObject 또는 ScaledJob을 생성하여 특정 이벤트 기반 확장을 정의
- KEDA Controller(Operator)가 ScaledObject를 감지하고, 정의된 이벤트 소스(예: Kafka, RabbitMQ)에서 메트릭을 수집
- KEDA의 Scaler가 이벤트 소스의 메트릭을 Kubernetes Metrics Adapter로 전달
- Kubernetes의 HPA가 KEDA의 데이터를 사용하여 Pod 개수를 조정
- 이벤트가 감소하면 KEDA는 Pod 개수를 줄이고, 필요 시 Pod를 0까지 축소
KEDA 설치
keda Helm chart를 설치하고, 배포된 리소스를 확인하겠습니다.
# KEDA Helm 설치
❯ cat <<EOT > keda-values.yaml
metricsServer:
useHostNetwork: true
prometheus:
metricServer:
enabled: true
port: 9022
portName: metrics
path: /metrics
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
operator:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
webhooks:
enabled: true
port: 8020
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus webhooks
enabled: true
EOT
❯ helm repo add kedacore https://kedacore.github.io/charts
❯ helm repo update
❯ helm install keda kedacore/keda --version 2.16.0 --namespace keda --create-namespace -f keda-values.yaml
❯ kubectl get pod -n keda
NAME READY STATUS RESTARTS AGE
keda-admission-webhooks-86cffccbf5-9cd8z 0/1 Running 0 27s
keda-operator-6bdffdc78-bnsf2 0/1 Running 1 (15s ago) 27s
keda-operator-metrics-apiserver-74d844d769-kxjqr 0/1 Running 0 27s
❯ kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1" | jq
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "external.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "externalmetrics",
"singularName": "",
"namespaced": true,
"kind": "ExternalMetricValueList",
"verbs": [
"get"
]
}
]
}
keda 네임스페이스에 테스트 어플리케이션을 생성하겠습니다.
테스트용 어플리케이션을 생성 후 ScaledObject 정책을 생성하겠습니다.
cat <<EOT > keda-cron.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: php-apache-cron-scaled
spec:
minReplicaCount: 0
maxReplicaCount: 2 # Specifies the maximum number of replicas to scale up to (defaults to 100).
pollingInterval: 30 # Specifies how often KEDA should check for scaling events
cooldownPeriod: 300 # Specifies the cool-down period in seconds after a scaling event
scaleTargetRef: # Identifies the Kubernetes deployment or other resource that should be scaled.
apiVersion: apps/v1
kind: Deployment
name: php-apache
triggers: # Defines the specific configuration for your chosen scaler, including any required parameters or settings
- type: cron
metadata:
timezone: Asia/Seoul
start: 00,15,30,45 * * * *
end: 05,20,35,50 * * * *
desiredReplicas: "1"
EOT
이 후 그라파나에 keda 전용 대시보드를 추가하고, (https://github.com/kedacore/keda/blob/main/config/grafana/keda-dashboard.json) 확인해보면, cron 트리거가 사용되어 특정 시간에만 pron-apache deployment가 배포 되는 것을 알 수 있습니다.
# cron ScaledObject 이 실행 되기 전
Every 2.0s: kubectl get ScaledObject,hpa,pod -n keda yujiyeon-ui-MacBookPro.local: 00:29:26
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX READY ACTIVE FALLBACK PAUSED TRIGGERS AUTHENTICATIONS AGE
scaledobject.keda.sh/php-apache-cron-scaled apps/v1.Deployment php-apache 0 2 True False False Unknown 7m9s
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-php-apache-cron-scaled Deployment/php-apache <unknown>/1 (avg) 1 2 0 7m9s
NAME READY STATUS RESTARTS AGE
pod/keda-admission-webhooks-86cffccbf5-9cd8z 1/1 Running 0 11m
pod/keda-operator-6bdffdc78-bnsf2 1/1 Running 1 (11m ago) 11m
pod/keda-operator-metrics-apiserver-74d844d769-kxjqr 1/1 Running 0 11m
# cron ScaledObject 이 실행 되었을 때
Every 2.0s: kubectl get ScaledObject,hpa,pod -n keda yujiyeon-ui-MacBookPro.local: 00:31:12
in 1.123s (0)
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX READY ACTIVE FALLBACK PAUSED TRIGGERS AUTHENTICATIONS AGE
scaledobject.keda.sh/php-apache-cron-scaled apps/v1.Deployment php-apache 0 2 True True False Unknown 8m54s
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/keda-hpa-php-apache-cron-scaled Deployment/php-apache <unknown>/1 (avg) 1 2 0 8m54s
NAME READY STATUS RESTARTS AGE
pod/keda-admission-webhooks-86cffccbf5-9cd8z 1/1 Running 0 13m
pod/keda-operator-6bdffdc78-bnsf2 1/1 Running 1 (13m ago) 13m
pod/keda-operator-metrics-apiserver-74d844d769-kxjqr 1/1 Running 0 13m
pod/php-apache-d87b7ff46-thkzm 1/1 Running 0 54s

'스터디 > AEWS' 카테고리의 다른 글
| [AEWS] 5주차 쿠버네티스 오토스케일링 이해하기 - 클러스터 오토스케일러 (CAS, CPA) (0) | 2025.03.09 |
|---|---|
| [AEWS] 5주차 쿠버네티스 오토스케일링 이해하기 - 수직 확장 (VPA) (0) | 2025.03.09 |
| [AEWS] 4주차 Grafana 이해하기 (0) | 2025.03.02 |
| [AEWS] 4주차 kube-prometheus-stack 설치 및 PromQL 쿼리 사용해보기 (0) | 2025.03.02 |
| [AEWS] 4주차 Kubernetes 이상징후에 알람 받기 (kwatch, botkube) (1) | 2025.03.02 |